네이버 서치어드바이저 - robot(로봇) 등록
네이버 서치어드바이저 - robot(로봇) 등록

네이버 서치 어드바이저에 접속한 후 웹마스터 가이드를 눌러줍니다.
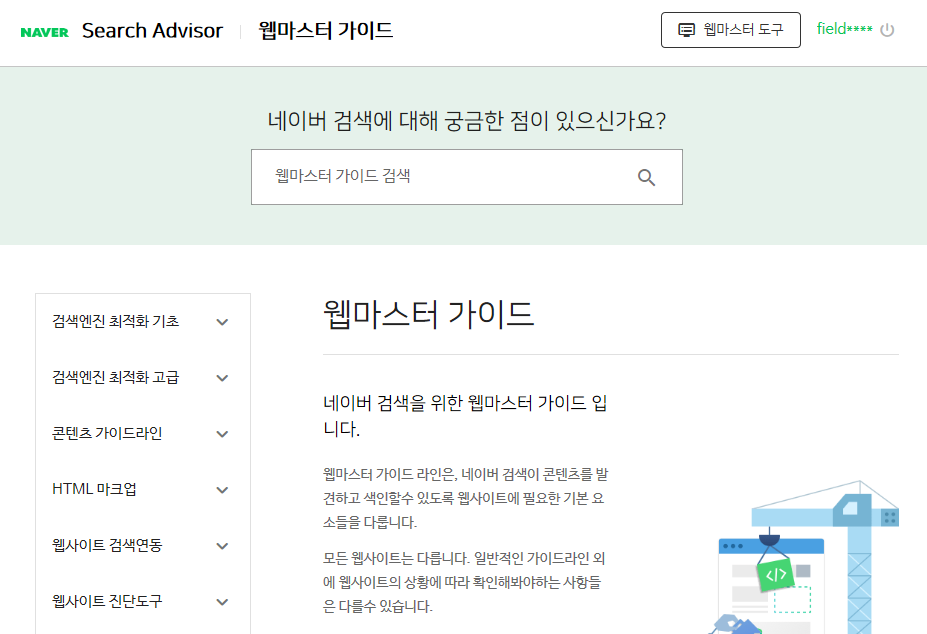
웹마스터 가이드에서 좌측 최상단에 있는 검색엔진 최적화 기초 항목을 눌러줍니다.

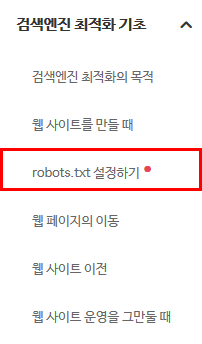
검색엔진 최적화 기초 항목을 누르면 아래에 검색엔진 최적화의 목적, 웹 사이트를 만들 때 아래에 robot.txt 설정하기가 있습니다. robot.txt 설정하기 버튼을 눌러줍니다.

우측에 보면 로봇(robot)을 등록할 블로그 주소를 찾아서 클릭해줍니다
.
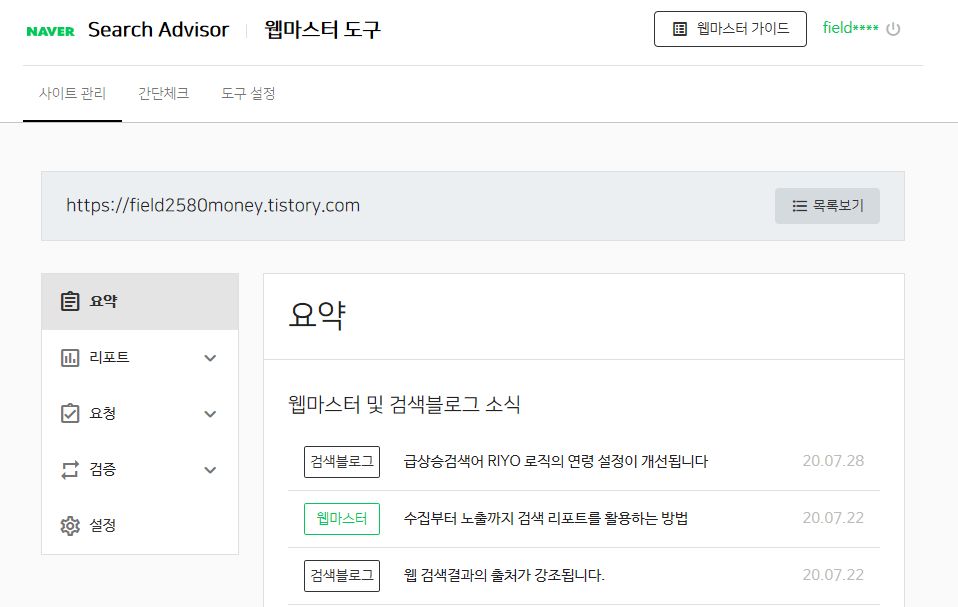
블로그 사이트 주소를 누르면 나오는 화면입니다.
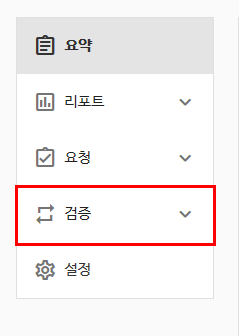
좌측 상단에 요약 항목안에 있는 검증 메뉴를 눌러줍니다.
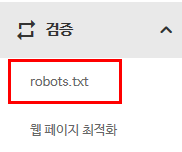
검증 메뉴를 누르면 robot.txt라는 메뉴가 나오는데 눌러줍니다.
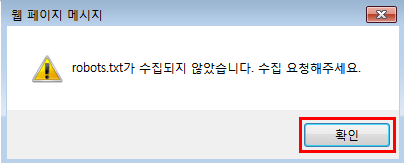
이렇게 누르면 robot.txt가 수집되지 않았습니다. 수집 요청해주세요라는 창이 나오는데 확인 버튼을 눌러줍니다.
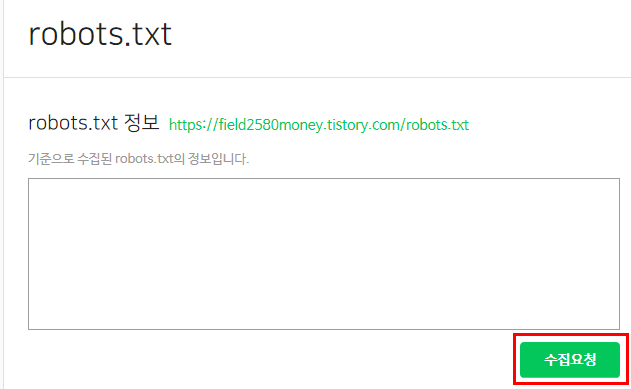
robot.txt 정보 (robot을 등록할 블로그나 사이트 주소)가 나옵니다. 그 아래에 기준으로 수집된 robot.txt의 정보입니다라는 안내창이 뜨고 우측 최하단에 보면 수집요청이 뜹니다. 이 버튼을 눌러주어야합니다.

수집요청 버튼을 누르면 수집요청 되었습니다. 업데이트에 일부 시간이 소요될 수 있습니다.라는 웹 페이지 메시지가 뜨고 확인 버튼을 눌러주면 됩니다.
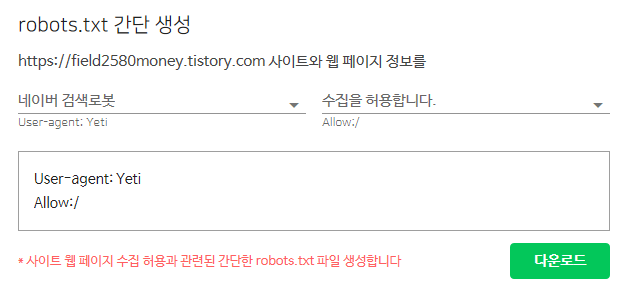
robot.txt 간단 생성에서 robot.txt를 다운받아 주어야하는데 네이버 검색로봇만 검색할지 아니면 모든 검색로봇이 검색되게끔 허용할지에 대한 설정을 해주어야 합니다.

저는 모든 검색로봇이 제 블로그 글을 봐야하기 때문에 네이버 검색로봇을 모든 검색로봇으로 바꾸겠습니다.
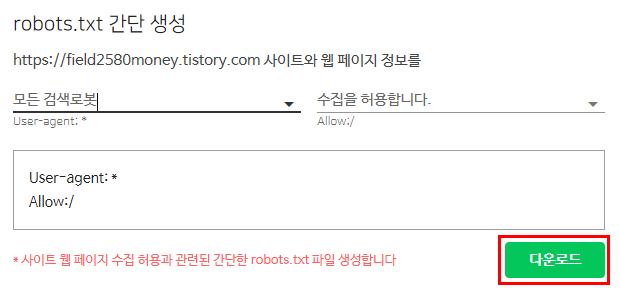
모든 검색로봇 수집을 허용합니다.로 바뀌었는지 제대로 확인해보고, 다운로드 항목을 눌러줍니다.

아래에 저장버튼을 눌러서 robot.txt 파일을 저장해줍니다.

티스토리 블로그에 들어가서 설정창으로 들어가주어야합니다. 티스토리 블로그에 접속한 후 오른쪽 상단에 있는 이모티콘을 눌러줍니다.
로봇(robot.txt)을 등록할 블로그 설정창 (톱니바퀴모양)을 눌러줍니다.
<구버전 글쓰기가 더이상 지원되지 않아서 새롭게 업데이트합니다.>
스킨 편집으로 가서 html 편집을 눌러주세요.

파일업로드를 눌러주세요.

하단에 +추가 버튼을 눌러주세요.
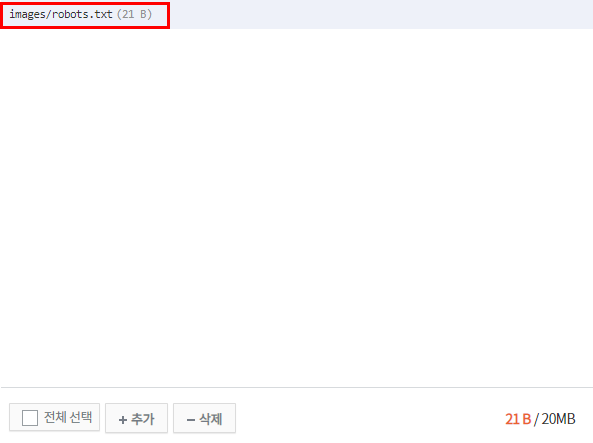
다운 받은 로봇 파일을 눌러주세요.
파일을 업로드한 후 한번 더 수집 요청을 눌러주세요.
수집요청 버튼을 누르면 수집요청 되었습니다. 업데이트에 일부 시간이 소요될 수 있습니다.라는 웹 페이지 메시지가 뜨고 확인 버튼을 눌러주면 됩니다.
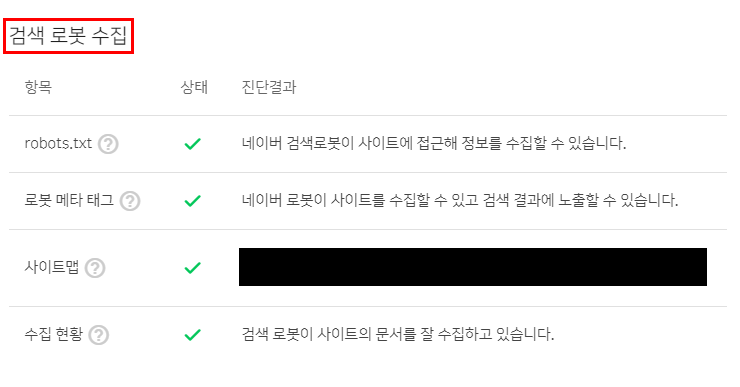
시간이 지나면 위와 같이 검색 로봇 수집이라는 항목에 들어가보면 정상적으로 로봇이 정보를 수집할 수 있습니다. 라는 진단결과가 뜹니다.
<아래에 설정에 있는 구버전 글쓰기를 이용한 업데이트는 더이상 지원하지 않기 때문에 위 포스팅을 참고해주시기바랍니다.>
robot.txt 파일의 경우 URL을 붙여넣기해야하는데 티스토리의 경우 새로 바뀐 글쓰기로 쓸 경우 Url 주소가 제대로 나오지 않기 때문에 티스토리 구버전 글쓰기를 이용해서 robot.txt 파일을 등록해야합니다. 구버전 글쓰기를 사용사는 방법은 티스토리 블로그 설정창에서 콘텐츠 설정 항목을 눌러줍니다.
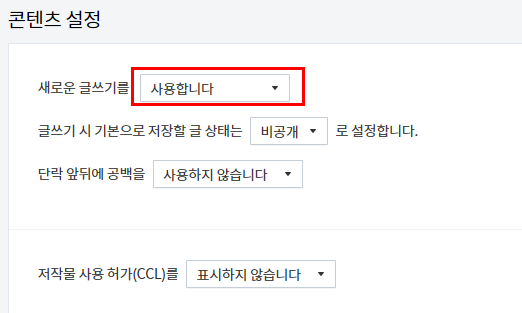
콘텐츠 설정에 새로운 글쓰기를 사용합니다.라는 글이 제일 첫줄에 있습니다. 사용합니다라는 창을 눌러줍니다.
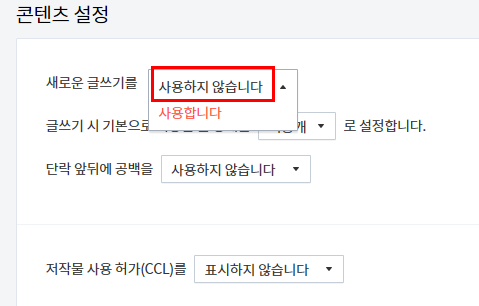
새로운 글쓰기는 신버전 글쓰기를 말하는 것이라서 저희는 구버전을 이용하기 위해서 사용하지 않습니다. 라는 글로 바꿔줍니다.
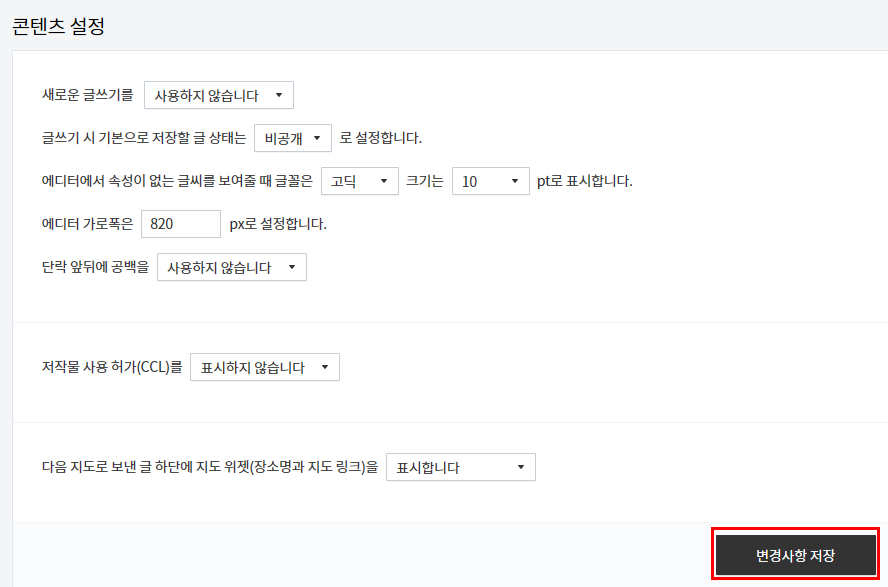
새로운 글쓰기를 사용하지 않습니다. 라고 바꿔주었으면 반드시 변경사항 저장을 눌러주셔야합니다. 변경사항 저장을 눌러주면 새로운 안내창이 뜨지않고 검정색인 바탕화면이 흰색으로 바뀌고 저장 완료라고 변경되니 반드시 확인해주어야합니다.
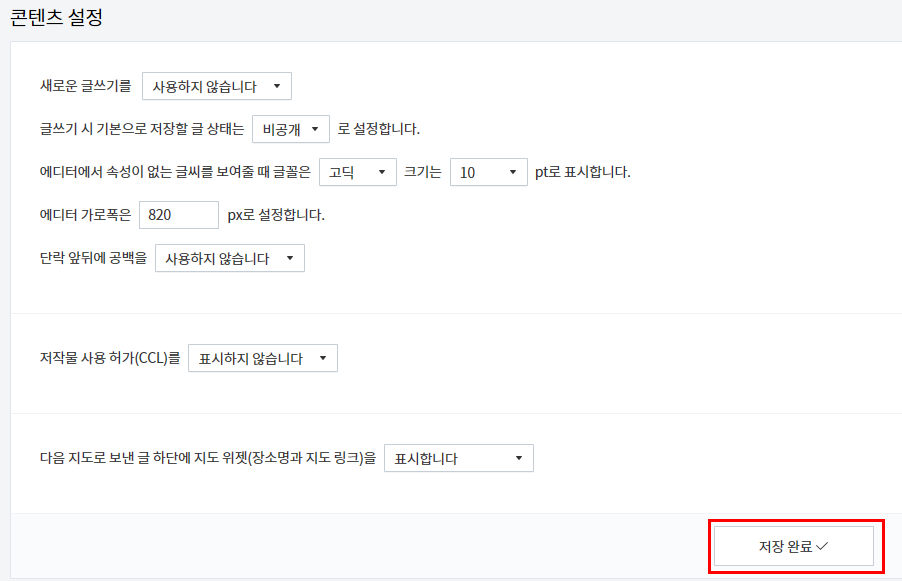
저장 완료라고 변경되었는지 확인해주어야합니다. 저장 완료가 되지않으면 구버전 글쓰기를 할 수 없습니다.

이제 robot.txt 파일을 올려주면기 됩니다. 우측 상단에 있는 글쓰기 버튼을 눌러줍니다.

메뉴 중간에 있는 파일 버튼을 눌러줍니다.
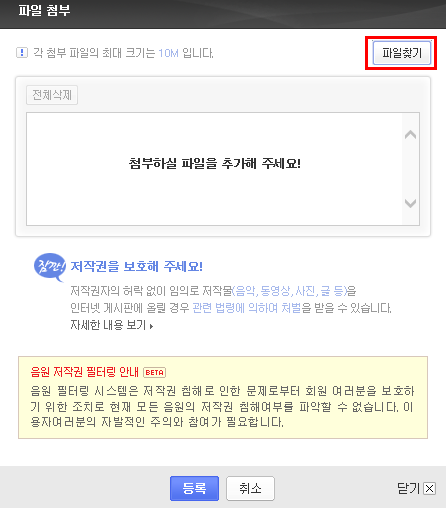
파일 찾기 버튼을 눌러줍니다.

방금 저장한 robot.txt파일을 불러준 후 등록버튼을 눌러줍니다.
robot.txt파일을 제대로 등록했다면 발행버튼을 눌러줍니다.
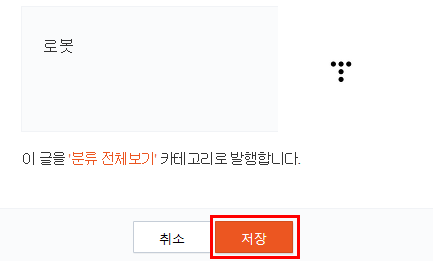
제목은 알기 쉽게 로봇으로 하였습니다. 저장을 눌러주면 robot.txt 파일이 내 블로그에 정상적으로 업로드 된 것입니다.
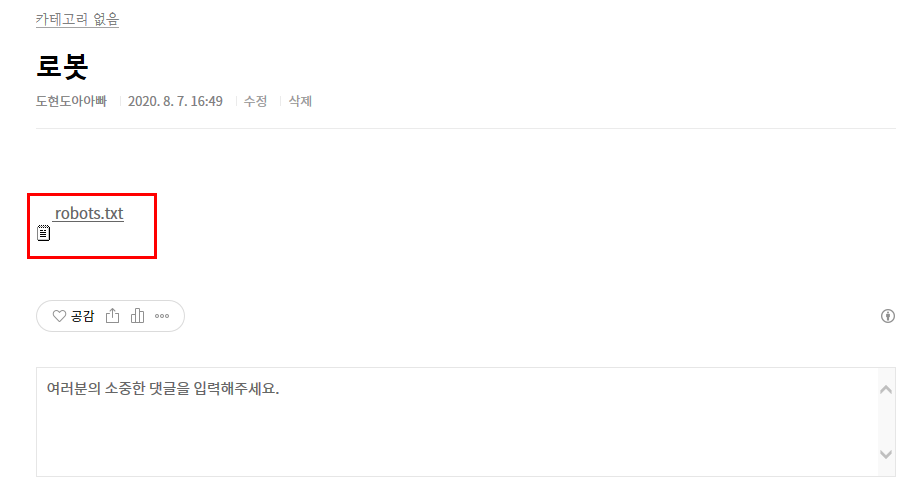
robot.txt 파일을 올린 글을 클릭해서 열어줍니다. 그 후에 robot.txt 파일을 오른쪽 마우스로 클릭해줍니다.
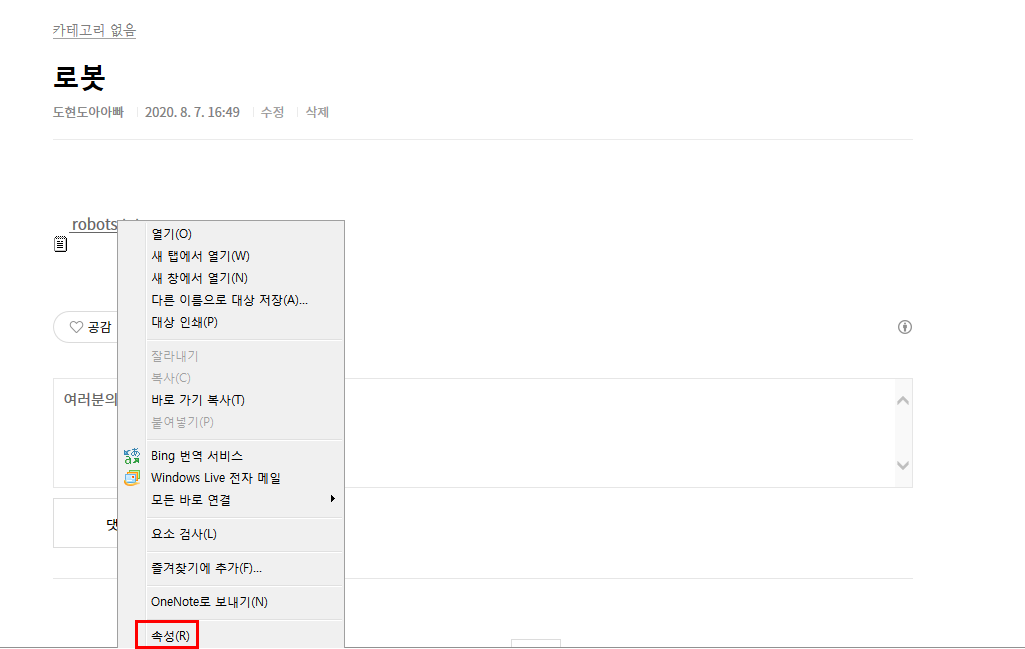
최하단에 있는 속성(R) 메뉴를 눌러줍니다.
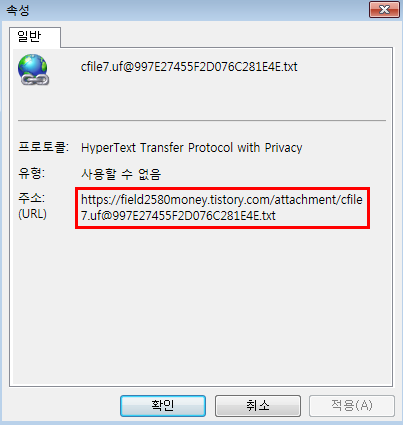
아래에 주소창에 있는 주소들을 복사해줍니다.
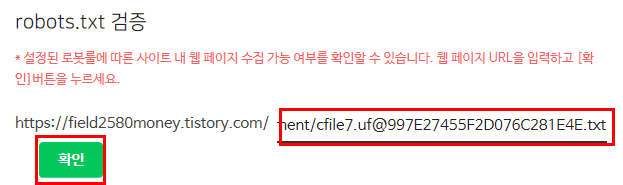
robot.txt 검증이라는 제목아래에는 설정된 로봇룰에 따른 사이트 내 웹페이지 수집 가능 여부를 확인할 수 있습니다. 웹 페이지 URL을 입력하고 [확인]버튼을 누르세요. 라는 창 아래에 내 블로그주소가 있습니다. 그 뒤에는 빈칸이 있는데 위에 복사했던 URL주소 중에서 내 블로그 주소를 제외한 나머지 부분들을 복사해서 붙여넣기 해줍니다. 그리고 확인 버튼을 눌러주면 완료됩니다.
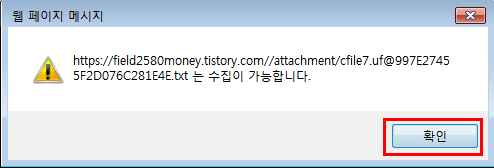
수집이 가능합니다. 라는 안내창이 뜨면 확인 버튼을 눌러주면 robot.txt등록이 완료됩니다.
ROBOT은 왜 등록해야하고 왜 중요한지에 대해서 알아보겠습니다.
다음 글들은 네이버 서치어드바이저 사이트에서 왜 robot.txt가 중요한지에 대해서 정리한 글입니다.
robots.txt 설정하기
robots.txt는 검색로봇에게 사이트 및 웹페이지를 수집할 수 있도록 허용하거나 제한하는 국제 권고안입니다. robots.txt 파일은 항상 사이트의 루트 디렉터리에 위치해야 하며 로봇 배제 표준을 따르는 일반 텍스트 파일로 작성해야 합니다. 네이버 검색로봇은 robots.txt에 작성된 규칙을 준수하며, 만약 사이트의 루트 디렉터리에 robots.txt 파일이 없다면 모든 콘텐츠를 수집할 수 있도록 간주합니다.
간혹 특정 목적을 위하여 개발된 웹 스크랩퍼를 포함하여 일부 불완전한 검색로봇은 robots.txt 내의 규칙을 준수하지 않을 수 있습니다. 그러므로 개인 정보를 포함하여 외부에 노출되면 안 되는 콘텐츠의 경우 로그인 기능을 통하여 보호하거나 다른 차단 방법을 사용해야 합니다.
robots.txt 위치
robots.txt 파일은 반드시 사이트의 루트 디렉터리에 위치해야 하며 텍스트 파일 (text/plain) 로 접근이 가능해야 합니다.
-
예) http://www.example.com/robots.txt
HTTP 응답코드에 따른 처리
사이트의 robots.txt에 네이버 검색로봇이 접근하였을 때 정상적인 2xx 응답 코드를 전달해주세요. 검색로봇은 HTTP 응답 코드에 따라 아래와 같이 동작합니다.
응답 코드 그룹설명
|
2xx |
Successful |
로봇 배제 표준을 준수하는 규칙을 해석하여 사용합니다. 만약, robots.txt가 HTML 문서로 반환된다면 그 안에 유효한 규칙이 있더라도 robots.txt가 없음 (모두 허용)으로 해석될 수도 있습니다. 그러므로, 로봇 배제 규칙을 따르는 일반 텍스트 파일 (text/plain)로 작성하는 것을 권장합니다. |
|
3xx |
Redirection |
HTTP redirect에 대하여 5회까지 허용하며 그 이상의 redirection 발생 시 중단 후 '모두 허용'으로 해석합니다. HTML 및 JavaScript를 통한 redirection은 해석하지 않습니다. |
|
4xx |
Client Error |
'모두 허용'으로 해석합니다. |
|
5xx |
Server Error |
'모두 허용하지 않음'으로 해석합니다. 다만, 이전에 정상적으로 수집된 robots.txt 규칙이 있다면 일시적으로 사용될 수 있습니다. |
robots.txt 규칙 예제
robots.txt 파일에 작성된 규칙은 같은 호스트, 프로토콜 및 포트 번호 하위의 페이지에 대해서만 유효합니다. http://www.example.com/robots.txt의 내용은 http://example.com/ 와 https://example.com/에는 적용되지 않습니다.
대표적인 규칙은 아래와 같으며 사이트의 콘텐츠 성격에 맞게 변경해주세요.
-
네이버 검색로봇만 수집 허용으로 설정합니다.User-agent: Yeti Allow: /
-
모든 검색엔진의 로봇에 대하여 수집 허용으로 설정합니다.User-agent: * Allow: /
-
사이트의 루트 페이지만 수집 허용으로 설정합니다.User-agent: * Disallow: / Allow: /$
-
관리자 페이지, 개인 정보 페이지와 같이 검색로봇 방문을 허용하면 안 되는 웹 페이지는 수집 비허용으로 설정해주세요. 아래 예제는 네이버 검색로봇에게 /private-image, /private-video 등은 수집하면 안 된다고 알려줍니다.User-agent: Yeti Disallow: /private*/
-
모든 검색로봇에게 사이트의 모든 페이지에 대하여 수집을 허용하지 않는다고 알려줍니다. 이 예제는 사이트의 어떠한 페이지도 수집 대상에 포함되지 않으므로 권장하지 않습니다.User-agent: * Disallow: /
자바스크립트 및 CSS 파일 수집을 허용해 주세요
간혹 일부 사이트가 자바스크립트 및 CSS 파일과 같은 리소스 URL을 robots.txt 규칙 내에서 수집 비허용으로 처리하는 경우가 있습니다. 이러한 경우 네이버 검색 로봇이 페이지의 주요 영역을 해석하는 데 어려움을 겪을 수 있습니다. 자바스크립트를 포함한 리소스 파일을 검색로봇이 수집할 수 있도록 허용해 주세요. 자세한 내용은 자바스크립트 검색 최적화 문서를 참고하시기 바랍니다.
파비콘(favicon) 수집을 허용해 주세요
"검색 결과에 노출"되는 웹페이지의 파비콘이 robots.txt로 차단된 경우 예외적으로 robots.txt 규칙을 따르지 않고 파비콘을 수집할 수 있습니다. 이는 파비콘을 검색 노출이 되고 있는 웹페이지 내부의 필수 구성 리소스로 취급하기 때문입니다. 검색에 노출되는 문서의 내부 구성요소(css, javascript, image..)는 문서와 동일하게 robots.txt 규칙으로 설정해 주세요. 파비콘과 관련된 좀 더 자세한 내용은 파비콘 마크업 가이드 을 참고하세요.
sitemap.xml 지정
내 사이트에 있는 페이지들의 목록이 담겨있는 sitemap.xml의 위치를 robots.txt에 기록해서 검색 로봇이 내 사이트의 콘텐츠를 더 잘 수집할 수 있도록 도울 수 있습니다.
User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
웹마스터도구의 robots.txt 도구를 활용하세요
웹마스터도구에서 제공하는 robots.txt 도구를 활용하면 보다 쉽게 사이트의 robots.txt 파일을 관리할 수 있으며 아래와 같이 2가지 기능을 제공합니다.
1. robots.txt 수집 및 검증

-
사이트의 루트 디렉터리에 있는 robots.txt 파일을 수정한 뒤 검색로봇에게 빠르게 알리고 싶다면 수집 요청을 눌러주세요
-
설정된 로봇룰에 따라서 웹 페이지의 수집 가능여부를 테스트할 수 있습니다.
2. robots.txt 간단 생성

-
robots.txt 파일을 간단하게 생성 후 다운로드할 수 있습니다. 다운로드한 robots.txt 파일을 사이트의 루트 디렉터리에 업로드 후 위 1번의 수집 요청을 실행하면 네이버 검색로봇이 바로 인식할 수 있습니다.
'인생공부 > 블로그 공부' 카테고리의 다른 글
| 구글 서치 콘솔 사용방법 (2) | 2020.08.21 |
|---|---|
| 티스토리 블로그 새 블로그 만들기 (하나 더 만드는 방법) (0) | 2020.08.19 |
| 줌/ZUM 사이트 검색등록 방법 - ZUM 에서 검색 노출 방법 (0) | 2020.08.18 |
| 네이버 서치 어드바이저 등록방법 (0) | 2020.08.17 |
| 네이버 서치어드바이저 RSS/사이트맵 등록방법 (0) | 2020.08.16 |